
什么是 AI Data Scientists?
Published:
什么是 AI Data Scientists
AI Data Scientists 是以 AI/LLM 为决策核心,自动完成端到端数据科学任务的智能体。
通常,它会调用代码解释器、数据库、可视化和机器学习工具,把“理解问题、感知数据、清洗特征、建模评估、生成报告”连成一个可执行闭环。
有什么用?
- 科学发现: 自动阅读数据、提出假设、运行实验、复现实证结果。
- 工业建模: 从业务数据到预测模型,自动完成清洗、特征、训练、评估和部署前检查。
- 商业分析: 面向自然语言问题生成 SQL、图表、归因分析和可解释报告。
- 个人助手: 帮个人处理表格、财务、健康、学习记录等小型数据任务。
与传统 AutoML 的区别
传统 AutoML 本质上更像一个被“人/Agent”调用的工具,主要加速模型选择、超参数调优、特征处理等局部环节;它通常依赖明确的数据、任务和评价指标,难以处理开放式建模问题,也无法完整覆盖从问题定义到报告生成的端到端流程。
AI Data Scientists 则更像任务主体:它可以理解开放世界中的分析目标,主动探索数据、调用工具、规划工作流、修正错误,并与人类协作或在监督下独立完成端到端数据科学任务。
核心框架
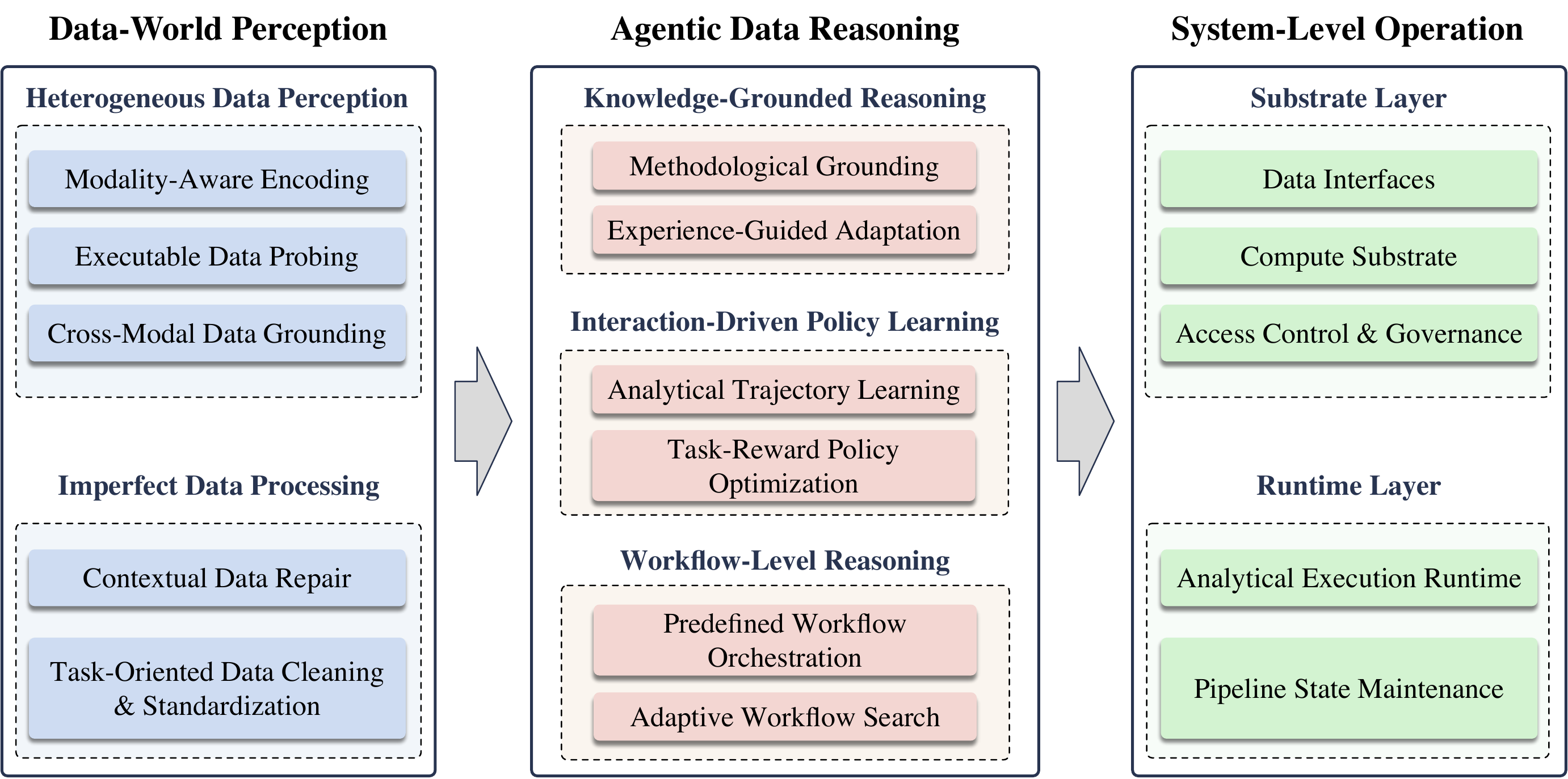
AI Data Scientists 可以看成三层协同:
- Data-World Perception: 感知真实数据世界,包括表格、文本、图像、时间序列、多源数据库,以及缺失、噪声、不一致等脏数据。
- Agentic Data Reasoning: 对数据科学方法做决策,包括任务拆解、建模选择、工作流规划、代码生成、实验反馈学习。
- System-Level Operation: 在真实系统中稳定执行,包括沙箱、工具调用、数据库连接、资源管理、日志、监控和安全治理。
关键挑战
数据感知很难。 真实数据往往没有干净 schema,存在多模态、多表、多源、缺失值、异常值和语义不一致。Agent 不只要“读到数据”,还要知道哪些数据可信、哪些变量有意义、哪些转换会改变结论。
复杂建模很难。 数据科学不是单步代码生成,而是长链路决策:选择问题形式、构造特征、比较模型、设计验证、解释误差、避免泄漏。任何一步错了,最后的高分或漂亮图表都可能是假的。
可靠执行很难。 Agent 会写代码、改数据、调用外部工具,也会犯错。因此需要可复现环境、权限控制、自动审计、失败恢复和人类确认机制。
总结
当前 AI Data Scientists 仍处于早期阶段。如何系统评估其真实能力,如何构造更强、更通用、更可靠的 agent,以及如何让它们在开放世界任务中与人类有效协作,仍然需要进一步探索。
Benchmark 与评估
目前还没有一个 benchmark 能完整覆盖真实的数据科学流程:DS-1000 更偏代码生成,MLE-bench 更偏 Kaggle 式机器学习工程,DABstep 和 KramaBench 更接近真实业务分析,而 DSGym、ResearchGym 进一步把工具、环境、执行轨迹和审计纳入评估。
| Benchmark | Year | Primary Focus | Task/Data Scale | Core Evaluation Style |
|---|---|---|---|---|
| DS-1000 [3] | 2023 | Data-science code generation | 1,000 problems spanning seven Python libraries | Executable tests and surface-form constraints; reliability against false positives |
| InfiAgent-DABench [4] | 2024 | Agentic data analysis on CSV files | Approximately 311 public validation questions over 55 CSV files; broader benchmark framework around DAEval | Closed-form correctness with sandboxed execution; accuracy metric |
| DSEval [5] | 2024 | Whole data-science lifecycle | Four benchmark families: Exercise, Stack Overflow, LeetCode, and Kaggle; 825 total problems across sets | Pass rate, error propagation, intactness, and presentation-error variants |
| TaskWeaver [6] | 2024 | Stateful data-analytics agent framework | 23 internal evaluation cases plus transformed DS-1000, DABench, and DSEval tasks | Normalized aggregate score across benchmark suites |
| MLAgentBench [7] | 2024 | End-to-end ML experimentation | 13 tasks across image, text, graph, tabular, time series, and recent research datasets | Success rate based on final artifact quality in controlled environments |
| DSBench [8] | 2024 | Realistic data analysis and modeling | 466 analysis tasks and 74 Kaggle-style modeling tasks | Accuracy for analysis; RPG and task success for modeling; human baselines included |
| DA-Code [9] | 2024 | Agent data-science code generation | 500 wrangling, ML, and EDA tasks | Total score, completion rate, executable-code rate |
| MLE-bench [10] | 2025 | ML engineering via Kaggle competitions | 75 competitions; Lite split of 22 competitions | Kaggle-style scoring mapped to leaderboard percentiles and Any Medal percentage |
| DataSciBench [11] | 2025 | Broad data-science prompt benchmark with fine-grained metrics | 23 evaluated models; 519 TFC test cases derived from curated prompts | Success rate, completion rate, VLM judging, 25 aggregate-function metrics, and total score |
| DABstep [12] | 2025 | Realistic multi-step data analysis with heterogeneous documents | 450+ enterprise data-analysis tasks from Adyen | Factoid-style automatic correctness; hard/easy split; cost reporting; public leaderboard |
| KramaBench [13] | 2025 | Data-to-insight pipelines over data lakes | 104 pipelines, 1,700 files, 24 sources, and 6 domains | End-to-end and subtask evaluation; exact/approximate string and numeric scoring; runtime per task |
| ScienceAgentBench [14] | 2025 | Data-driven scientific discovery workflows | 102 tasks from 44 papers in four disciplines | Generated Python programs scored by execution, results, and cost; multiple frameworks per model |
| PaperBench [15] | 2025 | Replicating frontier ML research papers | 20 ICML 2024 spotlight/oral papers | Hierarchical research-task rubrics for replication |
| AgentDS [16] | 2026 | Domain-specific data science and human-AI collaboration | 17 challenges across 6 industries; 29 teams and 80 participants | Competition ranking; AI-only versus human-AI comparison |
| DSGym [17] | 2026 | Standardized evaluation and training framework | Standardized/refined benchmark suite plus DSBio and DSPredict; 2,000-example training case study | Unified execution environments; quality and shortcut-solvability filtering |
| ResearchGym [18] | 2026 | Real-world AI research agents | 5 research environments and 39 subtasks | Improvement over strong baselines plus subtask completion in fixed containers |
参考文献
- Tang et al. LLM/Agent-as-Data-Analyst: A Survey. arXiv, 2025.
- Cao et al. Spider2-V: How Far Are Multimodal Agents from Automating Data Science and Engineering Workflows? NeurIPS, 2024.
- Lai et al. DS-1000: A Natural and Reliable Benchmark for Data Science Code Generation. ICML, 2023.
- Hu et al. InfiAgent-DABench: Evaluating Agents on Data Analysis Tasks. arXiv, 2024.
- Zhang et al. Benchmarking Data Science Agents. ACL, 2024.
- Qiao et al. TaskWeaver: A Code-First Agent Framework. arXiv, 2023.
- Huang et al. MLAgentBench: Evaluating Language Agents on Machine Learning Experimentation. arXiv, 2023.
- Jing et al. DSBench: How Far Are Data Science Agents from Becoming Data Science Experts? arXiv, 2024.
- Huang et al. DA-Code: Agent Data Science Code Generation Benchmark for Large Language Models. EMNLP, 2024.
- Chan et al. MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering. ICLR, 2025.
- Zhang et al. DataSciBench: An LLM Agent Benchmark for Data Science. arXiv, 2025.
- Egg et al. DABstep: Data Agent Benchmark for Multi-Step Reasoning. arXiv, 2025.
- Lai et al. KramaBench: A Benchmark for AI Systems on Data-to-Insight Pipelines over Data Lakes. arXiv, 2025.
- Chen et al. ScienceAgentBench: Toward Rigorous Assessment of Language Agents for Data-Driven Scientific Discovery. ICLR, 2025.
- Starace et al. PaperBench: Evaluating AI’s Ability to Replicate AI Research. arXiv, 2025.
- Luo et al. AgentDS Technical Report: Benchmarking the Future of Human-AI Collaboration in Domain-Specific Data Science. arXiv, 2026.
- Nie et al. DSGym: A Holistic Framework for Evaluating and Training Data Science Agents. arXiv, 2026.
- Garikaparthi et al. ResearchGym: Evaluating Language Model Agents on Real-World AI Research. arXiv, 2026.
BibTeX
@misc{liu2026autonomousdatascience,
title = {Towards Autonomous Data Science with LLM Agents: A Survey and Outlook},
author = {Liu, Fan and Han, Jindong and Lyu, Tengfei and Yang, Zherui and Liu, Hao},
year = {2026},
url = {https://luckyfan-cs.github.io/posts/2026/05/ai-data-scientists/}
}
What Are AI Data Scientists?
AI Data Scientists are agents that use AI/LLMs as the decision-making core to complete end-to-end data science tasks automatically.
In practice, they often call code interpreters, databases, visualization tools, and machine-learning toolkits, connecting problem understanding, data perception, cleaning, feature engineering, modeling, evaluation, and reporting into an executable loop.
What Are They Useful For?
- Scientific discovery: reading data, forming hypotheses, running experiments, and reproducing empirical findings.
- Industrial modeling: moving from business data to predictive models through automated cleaning, features, training, evaluation, and pre-deployment checks.
- Business analytics: generating SQL, charts, attribution analysis, and interpretable reports from natural-language questions.
- Personal assistants: helping individuals work with spreadsheets, finance logs, health records, learning traces, and other small datasets.
How Is This Different from Traditional AutoML?
Traditional AutoML is essentially a tool used by a human or an agent. It mainly accelerates local steps such as model selection, hyperparameter tuning, and feature processing. It usually assumes a well-defined dataset, task, and metric, so it struggles with open-ended modeling and only partially speeds up the broader data-science workflow.
AI Data Scientists are closer to task-level actors. They can interpret open-world analytical goals, explore data, call tools, plan workflows, fix errors, and complete end-to-end data science tasks either in collaboration with humans or autonomously under supervision.
Core Framework
AI Data Scientists can be viewed as a three-layer system:
- Data-World Perception: understanding real data worlds, including tables, text, images, time series, multi-source databases, missing values, noise, and inconsistent semantics.
- Agentic Data Reasoning: making data-science decisions, including task decomposition, modeling choices, workflow planning, code generation, and learning from experimental feedback.
- System-Level Operation: executing reliably in real systems, including sandboxes, tool calls, database connections, resource management, logs, monitoring, and safety governance.
Key Challenges
Data perception is hard. Real data rarely comes with clean schemas. It is often multimodal, multi-table, multi-source, incomplete, noisy, and semantically inconsistent. An agent must know not only what data exists, but also what is trustworthy, what variables matter, and which transformations may change the conclusion.
Complex modeling is hard. Data science is not one-step code generation. It is a long-horizon decision process: formulating the problem, constructing features, comparing models, designing validation, explaining errors, and avoiding leakage. A single wrong step can make the final score or chart misleading.
Reliable execution is hard. Agents write code, modify data, and call external tools, so they can also make operational mistakes. Deployment requires reproducible environments, access control, automatic auditing, failure recovery, and human confirmation when needed.
Summary
AI Data Scientists are still at an early stage. How to evaluate their real capabilities, how to build stronger, more general, and more reliable agents, and how to make them collaborate effectively with humans in open-world tasks remain open questions.
Benchmarks and Evaluation
No single benchmark fully covers the real data-science workflow today. DS-1000 focuses more on code generation, MLE-bench on Kaggle-style ML engineering, DABstep and KramaBench are closer to realistic business analytics, while DSGym and ResearchGym further include tools, environments, execution traces, and auditing.
| Benchmark | Year | Primary Focus | Task/Data Scale | Core Evaluation Style |
|---|---|---|---|---|
| DS-1000 [3] | 2023 | Data-science code generation | 1,000 problems spanning seven Python libraries | Executable tests and surface-form constraints; reliability against false positives |
| InfiAgent-DABench [4] | 2024 | Agentic data analysis on CSV files | Approximately 311 public validation questions over 55 CSV files; broader benchmark framework around DAEval | Closed-form correctness with sandboxed execution; accuracy metric |
| DSEval [5] | 2024 | Whole data-science lifecycle | Four benchmark families: Exercise, Stack Overflow, LeetCode, and Kaggle; 825 total problems across sets | Pass rate, error propagation, intactness, and presentation-error variants |
| TaskWeaver [6] | 2024 | Stateful data-analytics agent framework | 23 internal evaluation cases plus transformed DS-1000, DABench, and DSEval tasks | Normalized aggregate score across benchmark suites |
| MLAgentBench [7] | 2024 | End-to-end ML experimentation | 13 tasks across image, text, graph, tabular, time series, and recent research datasets | Success rate based on final artifact quality in controlled environments |
| DSBench [8] | 2024 | Realistic data analysis and modeling | 466 analysis tasks and 74 Kaggle-style modeling tasks | Accuracy for analysis; RPG and task success for modeling; human baselines included |
| DA-Code [9] | 2024 | Agent data-science code generation | 500 wrangling, ML, and EDA tasks | Total score, completion rate, executable-code rate |
| MLE-bench [10] | 2025 | ML engineering via Kaggle competitions | 75 competitions; Lite split of 22 competitions | Kaggle-style scoring mapped to leaderboard percentiles and Any Medal percentage |
| DataSciBench [11] | 2025 | Broad data-science prompt benchmark with fine-grained metrics | 23 evaluated models; 519 TFC test cases derived from curated prompts | Success rate, completion rate, VLM judging, 25 aggregate-function metrics, and total score |
| DABstep [12] | 2025 | Realistic multi-step data analysis with heterogeneous documents | 450+ enterprise data-analysis tasks from Adyen | Factoid-style automatic correctness; hard/easy split; cost reporting; public leaderboard |
| KramaBench [13] | 2025 | Data-to-insight pipelines over data lakes | 104 pipelines, 1,700 files, 24 sources, and 6 domains | End-to-end and subtask evaluation; exact/approximate string and numeric scoring; runtime per task |
| ScienceAgentBench [14] | 2025 | Data-driven scientific discovery workflows | 102 tasks from 44 papers in four disciplines | Generated Python programs scored by execution, results, and cost; multiple frameworks per model |
| PaperBench [15] | 2025 | Replicating frontier ML research papers | 20 ICML 2024 spotlight/oral papers | Hierarchical research-task rubrics for replication |
| AgentDS [16] | 2026 | Domain-specific data science and human-AI collaboration | 17 challenges across 6 industries; 29 teams and 80 participants | Competition ranking; AI-only versus human-AI comparison |
| DSGym [17] | 2026 | Standardized evaluation and training framework | Standardized/refined benchmark suite plus DSBio and DSPredict; 2,000-example training case study | Unified execution environments; quality and shortcut-solvability filtering |
| ResearchGym [18] | 2026 | Real-world AI research agents | 5 research environments and 39 subtasks | Improvement over strong baselines plus subtask completion in fixed containers |
References
- Tang et al. LLM/Agent-as-Data-Analyst: A Survey. arXiv, 2025.
- Cao et al. Spider2-V: How Far Are Multimodal Agents from Automating Data Science and Engineering Workflows? NeurIPS, 2024.
- Lai et al. DS-1000: A Natural and Reliable Benchmark for Data Science Code Generation. ICML, 2023.
- Hu et al. InfiAgent-DABench: Evaluating Agents on Data Analysis Tasks. arXiv, 2024.
- Zhang et al. Benchmarking Data Science Agents. ACL, 2024.
- Qiao et al. TaskWeaver: A Code-First Agent Framework. arXiv, 2023.
- Huang et al. MLAgentBench: Evaluating Language Agents on Machine Learning Experimentation. arXiv, 2023.
- Jing et al. DSBench: How Far Are Data Science Agents from Becoming Data Science Experts? arXiv, 2024.
- Huang et al. DA-Code: Agent Data Science Code Generation Benchmark for Large Language Models. EMNLP, 2024.
- Chan et al. MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering. ICLR, 2025.
- Zhang et al. DataSciBench: An LLM Agent Benchmark for Data Science. arXiv, 2025.
- Egg et al. DABstep: Data Agent Benchmark for Multi-Step Reasoning. arXiv, 2025.
- Lai et al. KramaBench: A Benchmark for AI Systems on Data-to-Insight Pipelines over Data Lakes. arXiv, 2025.
- Chen et al. ScienceAgentBench: Toward Rigorous Assessment of Language Agents for Data-Driven Scientific Discovery. ICLR, 2025.
- Starace et al. PaperBench: Evaluating AI’s Ability to Replicate AI Research. arXiv, 2025.
- Luo et al. AgentDS Technical Report: Benchmarking the Future of Human-AI Collaboration in Domain-Specific Data Science. arXiv, 2026.
- Nie et al. DSGym: A Holistic Framework for Evaluating and Training Data Science Agents. arXiv, 2026.
- Garikaparthi et al. ResearchGym: Evaluating Language Model Agents on Real-World AI Research. arXiv, 2026.
BibTeX
@misc{liu2026autonomousdatascience,
title = {Towards Autonomous Data Science with LLM Agents: A Survey and Outlook},
author = {Liu, Fan and Han, Jindong and Lyu, Tengfei and Yang, Zherui and Liu, Hao},
year = {2026},
url = {https://luckyfan-cs.github.io/posts/2026/05/ai-data-scientists/}
}