
AI Data Scientist 的评估瓶颈:Benchmark 不统一、环境不稳定、任务不够复杂
Published:
AI Data Scientist 的评估瓶颈:Benchmark 不统一、环境不稳定、任务不够复杂
如果要判断一个 AI Data Scientist 是否真的有能力,问题不能只停留在“它能不能写出一段分析代码”。真正困难的是:它能不能在一个真实、复杂、可复现的数据科学任务里,从理解问题、检查数据、选择方法、运行实验、解释结果到形成报告,稳定地做出高质量判断。
当前 AI Data Scientist 的一个核心瓶颈,是数据和评估体系还没有足够统一。不同 benchmark 对任务格式、运行环境、评分方式和结果产物的要求差异很大。这导致大家在评测同一个 agent 时,往往不只是在评测 agent 本身,也在评测 benchmark 的包装方式、Python 环境、依赖版本、资源限制、评分脚本,以及 agent 适配这些外部条件的能力。
当前到底在评估什么
评估 AI Data Scientist,至少包含六类能力:
- 问题理解:能否把业务问题或研究问题转成可执行的数据分析目标。
- 数据处理:能否读取、清洗、合并、检查缺失值、异常值和数据泄漏。
- 统计与建模:能否选择合理方法,而不是机械套用模型。
- 实验执行:能否运行代码、调参、比较方案,并处理运行错误。
- 结果解释:能否解释指标、置信度、偏差来源和结论边界。
- 可复现性:能否在相同约束下复现相同产物,或者解释差异来源。
现在很多评测只覆盖其中一部分。例如,有的更像代码生成评测,有的更像 Kaggle 式机器学习竞赛,有的关注数据分析问答,有的关注完整 agent 工作流。这些方向都有价值,但它们之间缺少一个足够通用的评估接口。
瓶颈一:Benchmark 格式不统一
不同 benchmark 的任务格式差异很大。一个任务可能是自然语言问题加 CSV 文件,另一个任务可能是 notebook、隐藏测试集、评分脚本、leaderboard metric、Docker 环境或多轮交互日志。对于人类研究者来说,这些差异还能手动适配;对于 DS agent 的系统评测来说,这会带来额外成本。
常见差异包括:
- 任务输入不统一:有的是单个 prompt,有的是 notebook,有的是 repo,有的是竞赛描述加数据目录。
- 输出产物不统一:有的要求最终答案,有的要求代码,有的要求预测文件,有的要求完整报告。
- 指标不统一:有的看 pass rate,有的看 leaderboard 分数,有的看人工打分,有的看单元测试或隐藏测试。
- 环境不统一:Python 版本、依赖包版本、CPU/GPU、内存、超时时间、是否允许联网都可能不同。
- 失败记录不统一:有的只给最终分数,有的保留轨迹、日志、代码 diff 和中间产物。
这会让评测变得很麻烦。一个 agent 在 benchmark A 上能跑,不代表它能自然迁移到 benchmark B。最后比较出来的结果,可能混入了大量“工程适配能力”,而不是纯粹的数据科学能力。
瓶颈二:数据科学 agent 对环境极其敏感
数据科学任务不是纯文本问答。它依赖运行时环境。Python 包版本变化、随机种子变化、底层数值库变化、硬件变化,甚至文件路径和系统 locale 的变化,都可能导致不同结果。
举一个简单例子:如果同一个任务依赖 pandas、numpy、scikit-learn、xgboost 或 lightgbm,包版本变化可能影响默认参数、warning 行为、数据类型推断、随机性控制和模型结果。对一个人类数据科学家来说,这些差异通常可以被识别和修正;但对 agent 来说,环境变化会影响它的观察、调试路径和最终产物。
所以评估 DS agent 时,沙盒环境不是附属项,而是评测对象的一部分。没有统一沙盒,就很难判断结果差异到底来自模型能力、agent 框架,还是环境差异。
瓶颈三:缺少复杂场景的数据科学任务
当前 benchmark 正在变多,但很多任务仍然偏短、偏干净、偏单轮,距离真实数据科学工作还有差距。
还有一层更基础的问题是数据本身的稀有性。高价值的数据科学任务通常绑定真实业务、用户行为、金融交易、医疗记录、工业流程或企业内部决策,这些数据往往同时具有隐私敏感性、获取成本高和不可公开复用的特点。也就是说,真正能检验 DS agent 能力的任务,不只是“难设计”,而是“难拿到、难公开、难长期维护”。即使是 Kaggle 这样世界上规模最大的数据科学竞赛平台,根据 Bönisch 和 Losaria 对 Kaggle 15 年竞赛生态的回顾,截至论文写作时也只是约托管了 10,000 场比赛。这说明高质量、可公开、可评分的数据科学任务本身就是稀缺资源。
真实场景通常有这些特点:
- 目标模糊:业务问题不一定直接等价于某个 metric。
- 数据脏:缺失、重复、异常值、单位不一致、时间窗口不一致很常见。
- 数据分散:多个表、多个来源、schema 不完整,需要理解实体关系。
- 数据稀有:高价值数据通常涉及隐私、商业机密或合规限制,很难被开放成 benchmark。
- 约束复杂:有成本、延迟、可解释性、合规、隐私和部署限制。
- 过程迭代:需要先探索,再建模,再复盘错误,再调整假设。
- 结论有边界:高分模型不一定代表可用结论,统计显著也不一定代表业务显著。
如果 benchmark 只评估“给定干净数据,输出一个答案或预测文件”,它很难覆盖 AI Data Scientist 最关键的能力:在不完美信息下做合理的数据判断。
一个可以做的实验
可以设计一个小实验,验证“环境和格式不统一会显著影响 DS agent 的评测结果”。
实验目标:
验证同一个 DS agent 在相同任务、不同环境和不同 benchmark 包装方式下,结果是否稳定。
实验设置:
- 选择任务集合:从代码生成型、数据分析型、机器学习竞赛型 benchmark 中各选 10 个任务,共 30 个任务。
- 统一任务格式:把每个任务转换成同一套 manifest,包括 prompt、数据路径、资源限制、期望产物和评分脚本。
- 构造多个环境:准备三个 Docker image,只改变少量依赖版本,例如 pandas、numpy、scikit-learn 或 lightgbm。
- 固定 agent:同一个模型、同一个 agent 框架、同一个工具权限、同一个 token budget。
- 重复运行:每个任务在每个环境下运行 3 次,记录最终分数、是否成功、错误类型、运行轨迹和产物 hash。
- 比较结果:观察分数方差、失败原因分布、产物一致性和环境敏感任务比例。
可以引入几个指标:
Environment Sensitivity = std(score across environments) / max(mean(score), epsilon)
Reproducibility Rate = same_result_runs / total_repeated_runs
Portability Rate = converted_tasks_without_custom_adapter / total_tasks
Failure Attribution = environment_error | agent_error | evaluator_error | ambiguous_task_error
如果实验结果显示,轻微包版本变化就会导致分数或结论大幅变化,那么说明当前评测并不只是模型能力问题,而是需要更强的环境约束和结果归因机制。
统一格式:给 DS agent benchmark 一个最小协议
一个可执行的 DS agent benchmark,可以采用如下目录结构:
task/
task.yaml
data/
evaluator/
score.py
sandbox/
Dockerfile
requirements.lock
rubric.md
expected_artifacts.json
task.yaml 至少应包含:
id: ds_task_001
title: customer_churn_analysis
task_type: exploratory_analysis | predictive_modeling | causal_analysis | reporting
input:
prompt: prompt.md
data_dir: data/
output:
required_files:
- report.md
- analysis.ipynb
- predictions.csv
evaluation:
scorer: evaluator/score.py
primary_metric: normalized_score
secondary_metrics:
- reproducibility
- runtime
- artifact_validity
sandbox:
dockerfile: sandbox/Dockerfile
lockfile: sandbox/requirements.lock
network: false
timeout_minutes: 60
cpu: 4
memory_gb: 16
logging:
save_agent_trace: true
save_stdout: true
save_artifacts: true
关键点不是把所有 benchmark 都改造成同一种任务,而是让它们暴露同一类元信息:
- 任务是什么。
- 数据在哪里。
- agent 可以使用什么工具。
- 运行环境是什么。
- 必须交付哪些产物。
- 评分脚本如何运行。
- 失败时如何归因。
这样,不同 benchmark 仍然可以保留自己的任务设计,但评测系统可以用同一套 runner、sandbox 和日志格式执行。
统一沙盒:评测 DS agent 的基础设施
统一沙盒应包含四层约束:
- 环境约束:固定 Python、系统库、核心依赖和随机种子策略。
- 资源约束:固定 CPU、GPU、内存、磁盘、超时时间和并发限制。
- 权限约束:默认禁止联网,数据目录只读,输出目录可写。
- 日志约束:保存命令、stdout、stderr、中间文件、最终文件和评分结果。
这类沙盒不是为了让任务变简单,而是为了让结果可比较。否则 benchmark 分数很难解释:一个 agent 得分高,可能只是因为它恰好运行在更合适的依赖版本上。
一个初步工作:DSLighting
为了解决上面这些问题,我们最近做了一个初步的数据科学 agent harness:DSLighting。它不是再提出一个新的单一 agent,而是把数据科学 agent 的任务接口、workflow 编排、执行控制和评估反馈显式拆开,让不同 agent 和不同 benchmark 可以在同一套 harness 里运行和比较。
第一步是 benchmark 规范化。DSLighting 目前已经支持 DACode (EMNLP 2024)、DABench (ICML 2024)、MoSciBench (ICLR 2026)、MLE-Bench 和 ScienceAgentBench (ICLR 2025) 的 benchmark evaluation。我们把这些不同来源、不同产物、不同评分脚本的数据科学任务整理成接近 MLE-bench 的统一格式:每个任务都有明确的任务描述、公开数据目录、期望输出产物、运行约束和 evaluator 接口。这样,benchmark 不再只是散落的脚本和数据,而是可以被统一 runner 调度、执行和复现的任务单元。
整体架构包含四层:
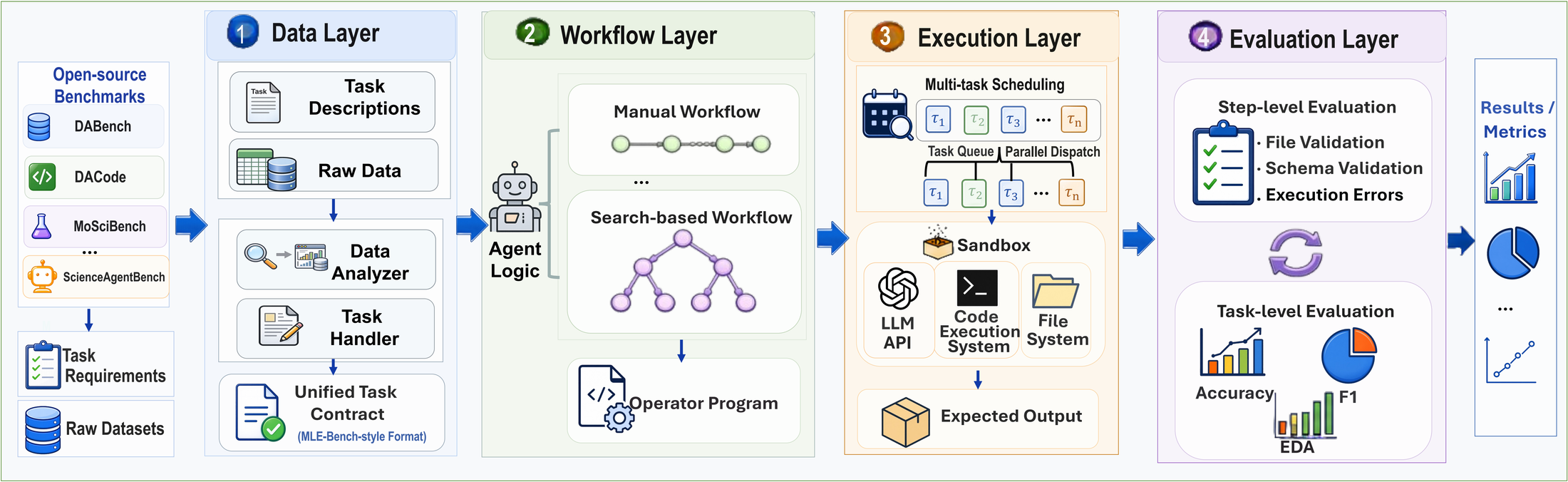
DSLighting 的四层 agent harness 框架:数据层、workflow 层、执行层和评估层。
- 数据层: 提供统一的任务接口,把原始数据、文件结构、schema、样例记录、输入输出要求和评分约束整理成 agent 可读的 task contract。它相当于给 agent 一个规范化的数据感知格式,减少“文件在哪里、要交什么、格式是什么”这类非模型能力错误。
- Workflow 层: 把不同 data science agent 的能力拆成原子化 operator,例如数据检查、计划、代码生成、执行、调试、验证和提交。这个设计有点像数学里的“基”:只要基足够清楚,就可以编排出不同形式的 agent,包括静态 workflow 和动态 workflow。
- 执行层: 在受控环境中执行代码、管理 workspace、保存中间状态,并支持并发运行不同任务。相比很多顺序执行的评测脚本,这种调度方式更适合大规模 benchmark evaluation。
- 评估层: 同时提供过程反馈和结果反馈。过程反馈检查中间产物、文件结构、schema 和运行错误;结果反馈调用官方 evaluator 或任务级评分脚本,给出最终指标。
这样做的直接收益有两个。第一,可以用同一套框架编排和比较不同 agent workflow,而不是为每个 agent 和 benchmark 写一套专用 glue code。第二,相比通用 agent 框架,DSLighting 尽量减少非模型思考导致的错误,例如任务格式理解错误、文件状态混乱、缺少必要输出、submission 格式不匹配和 evaluator 协议不一致。换句话说,它把一部分“系统噪声”从模型能力评估里剥离出来,让 benchmark 分数更接近 agent 的真实数据科学能力。
通过 DSBenchmark,benchmark evaluation 可以用几行代码启动:
from dotenv import load_dotenv
load_dotenv()
from dslighting.api import DSBenchmark
from dslighting.core import ConfigBuilder
config = ConfigBuilder().build_config(
workflow="aide",
model="gpt-4o",
)
benchmark = DSBenchmark("dabench", data_dir="/path/to/dabench")
result = benchmark.run(config=config)
print(result.results_path)
print(result.metadata_path)
一些初步实验结果
在相同任务接口、相同执行设置和官方 evaluator 下,DSLighting 在多个 benchmark 上达到最好或并列最好的结果。尤其是在更异构的任务上,harness 的影响会更明显。
| Harness | DABench | DACode | MoSciBench | ScienceAgentBench |
|---|---|---|---|---|
| VanillaHarness | 0.8521 | 0.3073 | 0.4659 | 0.1863 |
| LangChain | 0.8210 | 0.3013 | 0.5000 | 0.1373 |
| AutoGen | 0.7704 | 0.1974 | 0.1932 | 0.0980 |
| OpenHands | 0.7626 | 0.2361 | 0.3182 | 0.0882 |
| DSLighting | 0.8521 | 0.3709 | 0.6477 | 0.1961 |
这个结果说明:在 DABench 这种相对标准化的数据分析任务上,轻量 harness 已经可以达到较好表现;但在 DACode、MoSciBench 和 ScienceAgentBench 这类更依赖文件组织、代码执行、产物格式和评估协议的任务上,显式 harness 的优势更明显。
进一步看 ablation,去掉数据 grounding、执行治理或评估对齐都会明显降低整体表现:
| Setting | Macro Avg. | 关键现象 |
|---|---|---|
| Full DSLighting | 0.5167 | 完整 harness |
| w/o Data Grounding | 0.3721 | DACode 从 0.3709 降到 0.2376;MoSciBench 从 0.6477 降到 0.3750 |
| w/o Execution Governance | 0.2714 | 最大跌幅;DABench 从 0.8521 降到 0.2724 |
| w/o Evaluation Alignment | 0.3971 | MoSciBench 从 0.6477 降到 0.3409;ScienceAgentBench 从 0.1961 降到 0.0588 |
这组结果支持一个直接结论:很多失败并不是模型“不会思考”,而是数据没有被正确 grounding、执行状态没有被稳定管理、或者中间反馈没有和 evaluator 的成功标准对齐。
从效率上看,在 DABench 上复现 ReAct 时,LangChain ReAct 五个模型完整运行总耗时为 642.7 分钟,而 DSLighting ReAct 为 236.9 分钟,整体约 2.71 倍加速。失败模式分析也显示,DSLighting 主要减少的是任务 grounding、执行控制、评估对齐相关的可避免系统级失败,使剩余错误更集中在模型本身的能力边界上。
这只是第一步。更长期来看,DSLighting 这类 harness 的价值不只是“跑 benchmark 更方便”,而是把 agent 的数据感知、workflow 控制、执行状态和评估反馈变成可观察、可复现、可替换的系统组件。
更好的复杂任务应该长什么样
未来 AI Data Scientist benchmark 需要更多端到端任务。一个好的复杂任务不应该只问“预测准确率是多少”,而应该要求 agent 交付完整分析链路:
- 明确问题定义和假设。
- 审计数据质量。
- 解释特征工程选择。
- 运行基线模型和改进模型。
- 做错误分析和稳健性检查。
- 防止数据泄漏。
- 输出可读报告。
- 标注不确定性和结论边界。
评测也不应该只有一个最终分数。更合理的是组合评分:
Final Score =
0.30 * task_metric
+ 0.20 * data_quality_reasoning
+ 0.20 * methodology_validity
+ 0.15 * reproducibility
+ 0.10 * report_quality
+ 0.05 * resource_efficiency
不同任务可以调整权重,但必须显式声明。否则“能力强”这个结论会变得很模糊。
小结
AI Data Scientist 的评估瓶颈,不只是缺少更多 benchmark,而是缺少统一的评测协议、可复现的沙盒环境,以及足够复杂的真实数据科学任务。
DSLighting 是沿这个方向迈出的一步:先把异构 benchmark、agent workflow、执行环境和评估反馈放进同一个 harness,再逐步暴露哪些失败来自模型能力,哪些失败来自数据接口、执行状态和评估协议。
下一步可以从一个小实验开始:把多个 benchmark 的一小部分任务转成统一 manifest,在固定 agent 下比较不同环境和不同格式对结果的影响。这个实验不一定立刻产生新的 SOTA,但可以回答一个更基础的问题:我们现在看到的 benchmark 分数,到底有多少是在衡量 DS agent 的能力,又有多少是在衡量环境和评测格式本身。
如果这个问题回答不清楚,AI Data Scientist 的能力评估就很难真正进入工程化阶段。
参考资料
- OpenAI MLE-bench
- MLAgentBench
- DS-1000
- InfiAgent-DABench
- DataAgentBench
- DataSciBench
- DSLighting
- Bönisch, K. & Losaria, L. Kaggle Chronicles: 15 Years of Competitions, Community and Data Science Innovation. arXiv:2511.06304 (2025)
BibTeX
@misc{liu2026autonomousdatascience,
title = {Towards Autonomous Data Science with LLM Agents: A Survey and Outlook},
author = {Liu, Fan and Han, Jindong and Lyu, Tengfei and Yang, Zherui and Liu, Hao},
year = {2026},
url = {https://luckyfan-cs.github.io/posts/2026/05/ai-data-scientists/}
}
@misc{liu2026dslighting,
title = {DS-Lighting: Making Agent Harnesses Explicit for Data-Science Automation},
author = {Liu, Fan and Liu, Hao},
year = {2026},
url = {https://github.com/usail-hkust/dslighting}
}
Evaluation Bottlenecks for AI Data Scientists: Fragmented Benchmarks, Unstable Environments, and Insufficiently Complex Tasks
To judge whether an AI Data Scientist is truly capable, the question cannot stop at whether it can write a piece of analysis code. The real challenge is whether it can make stable, high-quality judgments in realistic, complex, and reproducible data-science tasks, moving from problem understanding, data inspection, method selection, and experiment execution to result interpretation and report generation.
A core bottleneck today is that data and evaluation systems are not unified enough. Different benchmarks vary substantially in task format, execution environment, scoring method, and expected artifacts. As a result, when researchers evaluate the same agent, they are often evaluating not only the agent itself, but also the benchmark wrapper, Python environment, dependency versions, resource limits, scoring scripts, and the agent’s ability to adapt to these external conditions.
What Are We Actually Evaluating?
Evaluating an AI Data Scientist requires at least six types of capabilities:
- Problem understanding: whether it can translate a business or research question into an executable data-analysis objective.
- Data handling: whether it can read, clean, merge, and inspect data for missing values, outliers, and leakage.
- Statistical and modeling judgment: whether it can choose reasonable methods instead of mechanically applying models.
- Experiment execution: whether it can run code, tune parameters, compare alternatives, and handle runtime errors.
- Result interpretation: whether it can explain metrics, confidence, sources of bias, and boundaries of conclusions.
- Reproducibility: whether it can reproduce the same artifacts under the same constraints, or explain why differences appear.
Many current evaluations cover only part of this space. Some look more like code-generation benchmarks, some like Kaggle-style machine-learning competitions, some focus on data-analysis question answering, and some target complete agent workflows. All of these directions are useful, but they lack a sufficiently general evaluation interface.
Bottleneck 1: Benchmark Formats Are Not Unified
Benchmark task formats differ widely. One task may be a natural-language question plus CSV files, while another may involve a notebook, hidden test set, scoring script, leaderboard metric, Docker environment, or multi-turn interaction logs. Human researchers can still adapt to these differences manually, but systematic evaluation of DS agents pays an additional cost.
Common differences include:
- Inconsistent task inputs: a single prompt, a notebook, a repository, or a competition description plus a data directory.
- Inconsistent output artifacts: final answers, code, prediction files, or complete reports.
- Inconsistent metrics: pass rate, leaderboard score, human grading, unit tests, or hidden tests.
- Inconsistent environments: Python versions, dependency versions, CPU/GPU access, memory, timeout, and network permissions.
- Inconsistent failure records: some benchmarks only report a final score, while others preserve traces, logs, code diffs, and intermediate artifacts.
This makes evaluation difficult. An agent that runs on benchmark A does not necessarily transfer naturally to benchmark B. The final comparison may include a large amount of engineering adaptation ability rather than pure data-science capability.
Bottleneck 2: Data-Science Agents Are Highly Environment-Sensitive
Data-science tasks are not pure text question answering. They depend on runtime environments. Changes in Python package versions, random seeds, numerical libraries, hardware, file paths, and even system locale can lead to different outcomes.
For example, if the same task depends on pandas, numpy, scikit-learn, xgboost, or lightgbm, package-version changes may affect default parameters, warning behavior, dtype inference, randomness control, and model results. A human data scientist can usually identify and fix these differences. For an agent, however, environment changes affect what it observes, how it debugs, and what it eventually produces.
Therefore, when evaluating DS agents, the sandbox is not an accessory. It is part of the evaluation object. Without a unified sandbox, it is hard to determine whether differences come from model capability, the agent framework, or the environment.
Bottleneck 3: Complex Data-Science Tasks Are Scarce
The number of benchmarks is increasing, but many tasks remain short, clean, and single-turn. They are still far from real data-science work.
There is also a more fundamental issue: valuable data-science data is scarce. High-value data-science tasks are often tied to real businesses, user behavior, financial transactions, medical records, industrial processes, or internal enterprise decisions. These datasets tend to be privacy-sensitive, costly to obtain, and difficult to release for public reuse. In other words, tasks that truly test DS agents are not merely hard to design; they are hard to obtain, hard to publish, and hard to maintain over time. Even Kaggle, one of the world’s largest data-science competition platforms, had hosted only about 10,000 competitions at the time discussed in Bönisch and Losaria’s 15-year review of Kaggle’s competition ecosystem. This illustrates that high-quality, public, scoreable data-science tasks are themselves a scarce resource.
Real scenarios usually have the following properties:
- Ambiguous goals: a business question is not always equivalent to a single metric.
- Dirty data: missing values, duplicates, outliers, inconsistent units, and inconsistent time windows are common.
- Distributed data: multiple tables, multiple sources, incomplete schemas, and entity relationships must be understood.
- Scarce data: high-value data often involves privacy, trade secrets, or compliance constraints, making it difficult to turn into open benchmarks.
- Complex constraints: cost, latency, interpretability, compliance, privacy, and deployment constraints matter.
- Iterative process: agents must explore, model, review errors, and revise hypotheses.
- Bounded conclusions: a high-scoring model does not necessarily imply a usable conclusion, and statistical significance does not necessarily imply business significance.
If a benchmark only asks for an answer or prediction file from clean data, it cannot cover the most important ability of an AI Data Scientist: making reasonable data judgments under imperfect information.
A Feasible Experiment
We can design a small experiment to test whether inconsistent environments and formats significantly affect DS-agent evaluation results.
Experiment goal:
Test whether the same DS agent produces stable results on the same tasks under different environments and benchmark wrappers.
Experimental setup:
- Select a task set: choose 10 tasks each from code-generation, data-analysis, and machine-learning competition benchmarks, for 30 tasks in total.
- Unify task format: convert each task into the same manifest format, including prompt, data path, resource limits, expected artifacts, and scoring script.
- Build multiple environments: prepare three Docker images that change only a small number of dependencies, such as pandas, numpy, scikit-learn, or lightgbm.
- Fix the agent: use the same model, agent framework, tool permissions, and token budget.
- Repeat runs: run each task three times in each environment, recording final score, success status, error type, execution trace, and artifact hashes.
- Compare results: inspect score variance, failure-cause distribution, artifact consistency, and the proportion of environment-sensitive tasks.
Several metrics can be introduced:
Environment Sensitivity = std(score across environments) / max(mean(score), epsilon)
Reproducibility Rate = same_result_runs / total_repeated_runs
Portability Rate = converted_tasks_without_custom_adapter / total_tasks
Failure Attribution = environment_error | agent_error | evaluator_error | ambiguous_task_error
If the experiment shows that small package-version changes cause large changes in scores or conclusions, then current evaluation is not only a model-capability problem. It also needs stronger environment constraints and result-attribution mechanisms.
Unified Format: A Minimal Protocol for DS-Agent Benchmarks
An executable DS-agent benchmark can use the following directory structure:
task/
task.yaml
data/
evaluator/
score.py
sandbox/
Dockerfile
requirements.lock
rubric.md
expected_artifacts.json
task.yaml should contain at least:
id: ds_task_001
title: customer_churn_analysis
task_type: exploratory_analysis | predictive_modeling | causal_analysis | reporting
input:
prompt: prompt.md
data_dir: data/
output:
required_files:
- report.md
- analysis.ipynb
- predictions.csv
evaluation:
scorer: evaluator/score.py
primary_metric: normalized_score
secondary_metrics:
- reproducibility
- runtime
- artifact_validity
sandbox:
dockerfile: sandbox/Dockerfile
lockfile: sandbox/requirements.lock
network: false
timeout_minutes: 60
cpu: 4
memory_gb: 16
logging:
save_agent_trace: true
save_stdout: true
save_artifacts: true
The key is not to force all benchmarks into the same task design, but to make them expose the same kind of metadata:
- What the task is.
- Where the data is.
- Which tools the agent may use.
- What the runtime environment is.
- Which artifacts must be delivered.
- How the scoring script is run.
- How failures should be attributed.
This allows different benchmarks to preserve their own task designs while enabling one runner, sandbox, and logging format to execute them.
Unified Sandboxes: Infrastructure for Evaluating DS Agents
A unified sandbox should include four layers of constraints:
- Environment constraints: fixed Python, system libraries, core dependencies, and random-seed policy.
- Resource constraints: fixed CPU, GPU, memory, disk, timeout, and concurrency limits.
- Permission constraints: network disabled by default, read-only data directory, writable output directory.
- Logging constraints: save commands, stdout, stderr, intermediate files, final files, and scoring results.
This kind of sandbox is not meant to make tasks easier. It is meant to make results comparable. Otherwise benchmark scores are hard to interpret: an agent may score well simply because it happened to run under a more favorable dependency version.
An Initial Step: DSLighting
To address these issues, we recently built an initial data-science agent harness: DSLighting. It is not another single agent. Instead, it makes the task interface, workflow orchestration, execution control, and evaluation feedback explicit, so that different agents and different benchmarks can be run and compared inside the same harness.
The first step is benchmark normalization. DSLighting now supports benchmark evaluation for DACode (EMNLP 2024), DABench (ICML 2024), MoSciBench (ICLR 2026), MLE-Bench, and ScienceAgentBench (ICLR 2025). These benchmarks come with different task sources, artifacts, and grading scripts, so we organize them into a unified format close to MLE-bench: each task has a clear task description, public data directory, expected output artifacts, runtime constraints, and evaluator interface. In this form, a benchmark is no longer just a collection of scripts and files, but a task unit that can be scheduled, executed, and reproduced by a unified runner.
The overall architecture has four layers:
The four-layer DSLighting agent harness: data, workflow, execution, and evaluation.
- Data layer: provides a unified task interface by converting raw data, file layouts, schemas, sample records, input-output requirements, and scoring constraints into an agent-readable task contract. This gives the agent a normalized data-perception format and reduces non-model failures such as not knowing where files are, what to submit, or which format is required.
- Workflow layer: decomposes the capabilities of data-science agents into atomic operators, such as data inspection, planning, code generation, execution, debugging, validation, and submission. This is similar to the idea of a basis in mathematics: once the basis is clear, many forms of agents can be composed, including static workflows and dynamic workflows.
- Execution layer: executes code in a controlled environment, manages the workspace, preserves intermediate state, and supports concurrent execution across tasks. Compared with many sequential benchmark runners, this scheduling model is more suitable for large-scale benchmark evaluation.
- Evaluation layer: provides both process feedback and result feedback. Process feedback checks intermediate artifacts, file structures, schemas, and runtime errors; result feedback calls the official evaluator or task-level scoring script to produce final metrics.
This design has two direct benefits. First, different agent workflows can be orchestrated and compared in one framework, instead of writing separate glue code for every agent-benchmark pair. Second, compared with general-purpose agent frameworks, DSLighting reduces failures that are not caused by model reasoning itself, such as task-format misunderstanding, inconsistent file state, missing required outputs, submission-format mismatch, and evaluator-protocol mismatch. In other words, it removes part of the system noise from model-capability evaluation, making benchmark scores closer to the agent’s real data-science capability.
With DSBenchmark, benchmark evaluation can be launched in just a few lines:
from dotenv import load_dotenv
load_dotenv()
from dslighting.api import DSBenchmark
from dslighting.core import ConfigBuilder
config = ConfigBuilder().build_config(
workflow="aide",
model="gpt-4o",
)
benchmark = DSBenchmark("dabench", data_dir="/path/to/dabench")
result = benchmark.run(config=config)
print(result.results_path)
print(result.metadata_path)
Initial Experimental Evidence
Under the same task interface, execution setting, and official evaluators, DSLighting achieves the best or tied-best results across several benchmarks. The effect is especially visible on more heterogeneous tasks.
| Harness | DABench | DACode | MoSciBench | ScienceAgentBench |
|---|---|---|---|---|
| VanillaHarness | 0.8521 | 0.3073 | 0.4659 | 0.1863 |
| LangChain | 0.8210 | 0.3013 | 0.5000 | 0.1373 |
| AutoGen | 0.7704 | 0.1974 | 0.1932 | 0.0980 |
| OpenHands | 0.7626 | 0.2361 | 0.3182 | 0.0882 |
| DSLighting | 0.8521 | 0.3709 | 0.6477 | 0.1961 |
This suggests that lightweight harnesses can already work well on relatively standardized data-analysis tasks such as DABench. However, on DACode, MoSciBench, and ScienceAgentBench, where tasks depend more heavily on file organization, code execution, artifact format, and evaluation protocol, an explicit data-science harness becomes more useful.
The ablation study tells the same story: removing data grounding, execution governance, or evaluation alignment all substantially reduces performance.
| Setting | Macro Avg. | Key Observation |
|---|---|---|
| Full DSLighting | 0.5167 | Complete harness |
| w/o Data Grounding | 0.3721 | DACode drops from 0.3709 to 0.2376; MoSciBench drops from 0.6477 to 0.3750 |
| w/o Execution Governance | 0.2714 | Largest decline; DABench drops from 0.8521 to 0.2724 |
| w/o Evaluation Alignment | 0.3971 | MoSciBench drops from 0.6477 to 0.3409; ScienceAgentBench drops from 0.1961 to 0.0588 |
These results support a direct conclusion: many failures are not simply caused by the model being unable to reason. They come from data not being grounded correctly, execution state not being managed reliably, or intermediate feedback not being aligned with the evaluator’s success criterion.
On efficiency, when reproducing ReAct on DABench, LangChain ReAct takes 642.7 minutes across five complete model runs, while DSLighting ReAct takes 236.9 minutes, giving about a 2.71x speedup. Failure-mode analysis also shows that DSLighting mainly reduces avoidable system-level failures related to task grounding, execution control, and evaluation alignment, pushing the remaining errors closer to intrinsic model-capability limits.
This is only a first step. In the longer run, the value of harnesses such as DSLighting is not merely that they make benchmarks easier to run. They also turn data perception, workflow control, execution state, and evaluation feedback into observable, reproducible, and replaceable system components.
What Better Complex Tasks Should Look Like
Future AI Data Scientist benchmarks need more end-to-end tasks. A good complex task should not only ask for prediction accuracy. It should require the agent to deliver a complete analysis chain:
- Define the problem and assumptions clearly.
- Audit data quality.
- Explain feature-engineering choices.
- Run baseline and improved models.
- Perform error analysis and robustness checks.
- Prevent data leakage.
- Produce a readable report.
- Mark uncertainty and the boundaries of conclusions.
Evaluation should also not rely on a single final score. A more reasonable approach is a composite score:
Final Score =
0.30 * task_metric
+ 0.20 * data_quality_reasoning
+ 0.20 * methodology_validity
+ 0.15 * reproducibility
+ 0.10 * report_quality
+ 0.05 * resource_efficiency
Different tasks can adjust the weights, but they must declare them explicitly. Otherwise, the conclusion that an agent is “strong” becomes vague.
Summary
The evaluation bottleneck of AI Data Scientists is not only the lack of more benchmarks. It is the lack of unified evaluation protocols, reproducible sandbox environments, and sufficiently complex real data-science tasks.
DSLighting is one step in this direction: it first brings heterogeneous benchmarks, agent workflows, execution environments, and evaluation feedback into the same harness, then makes it easier to separate failures caused by model capability from failures caused by data interfaces, execution state, and evaluation protocols.
A practical next step is to start with a small experiment: convert a subset of tasks from multiple benchmarks into a unified manifest, then compare the effects of different environments and formats under a fixed agent. This experiment may not immediately produce a new SOTA result, but it can answer a more basic question: how much of the benchmark score we see today measures DS-agent capability, and how much measures the environment and evaluation format themselves?
If this question cannot be answered clearly, evaluating AI Data Scientist capability will remain difficult to engineer in a reliable way.
Resources
- OpenAI MLE-bench
- MLAgentBench
- DS-1000
- InfiAgent-DABench
- DataAgentBench
- DataSciBench
- DSLighting
- Bönisch, K. & Losaria, L. Kaggle Chronicles: 15 Years of Competitions, Community and Data Science Innovation. arXiv:2511.06304 (2025)
BibTeX
@misc{liu2026autonomousdatascience,
title = {Towards Autonomous Data Science with LLM Agents: A Survey and Outlook},
author = {Liu, Fan and Han, Jindong and Lyu, Tengfei and Yang, Zherui and Liu, Hao},
year = {2026},
url = {https://luckyfan-cs.github.io/posts/2026/05/ai-data-scientists/}
}
@misc{liu2026dslighting,
title = {DS-Lighting: Making Agent Harnesses Explicit for Data-Science Automation},
author = {Liu, Fan and Liu, Hao},
year = {2026},
url = {https://github.com/usail-hkust/dslighting}
}